

在AI计算负载日益流行的今天,训练和推理这两种不同的AI计算形式已经日益为人们所熟悉。虽然在AI应用兴起的早期,NVIDIA的通用GPU在训练和推理这两个计算领域都曾一统天下。但随着CPU、FPGA和各类AI专用芯片在架构上进行有针对性的调整,AI推理计算已经不再是GPU所独有的能力了。尤其是从Skylake开始的最近几代Xeon-SP处理器上,Intel逐渐增加了称为DL Boot的AI负载计算能力,使得CPU在AI推理计算方面也占据了一席之地。
在第一代DL Boot技术上,Intel主要是通过增加几条AVX512 VNNI指令集扩展指令的方式,来加速卷积神经网络里面的向量计算。在第二代DL Boot技术上,Intel进一步引入了新的BF16数据格式。这一数据格式不仅不会增加数据存储所占用的空间,还能有效地提高神经网络计算过程中的数据精度。与BF16数据格式相配套,Intel又一次在AVX512指令集里增加了一系列对应的新指令。
通过两代DL Boot技术,Intel Xeon CPU已经能够很好地对AI负载的推理计算进行加速。于是现在我们经常会看到,一些纯CPU的服务器也能够运行一些中小规模的AI模型进行推理分析,并在可接受的延时范围内获得较高精度的结果。
但Intel的雄心显然不会只局限在AI推理方面,使用CPU对AI训练计算进行加速,使得一些中小型AI模型也能够在CPU上进行训练,这是Intel期望达到的技术和市场目标。毕竟,相比于NVIDIA T4这样价格在万元以上的独立GPU卡而言,CPU的成本要便宜很多。于是,按照Intel的规划,第三代DL Boot技术AMX(Advanced Matrix Extension:高级矩阵扩展)功能即将在新一代的Sapphire Rapids CPU上推出。

使用AMX技术后Sapphire Rapids CPU对AI计算的加速性能
在不久前结束的2021 Architect Day上,Intel展示了AMX对于不同数据格式所带来的计算性能提升的最新进展。相比于只是在AVX512指令集基础上进行指令扩展的前两代DL Boot技术而言,作为具有自身存储和操作的独立扩展功能,AMX可以极大地增强x86 CPU针对矩阵的运算能力,其复杂性要远超前两代DL Boot技术。
根据Intel的介绍,AMX引入了一个新的矩阵寄存器文件,其中包含8个秩为2的张量(矩阵)寄存器,称为tiles,命名为TMM0…TMM7。每个tiles的最大大小为16行乘64字节列,总大小为1 KiB /寄存器,整个寄存器文件的总大小为8 KiB。通过tiles控制寄存器(TILECFG),用户可以根据行数和每行字节数来配置这些tiles的大小。这样一来,根据所实施的神经网络算法的不同,用户可以使得配置后的tiles的大小能够更自然地表示对应的算法,从而取得最好的计算效率。
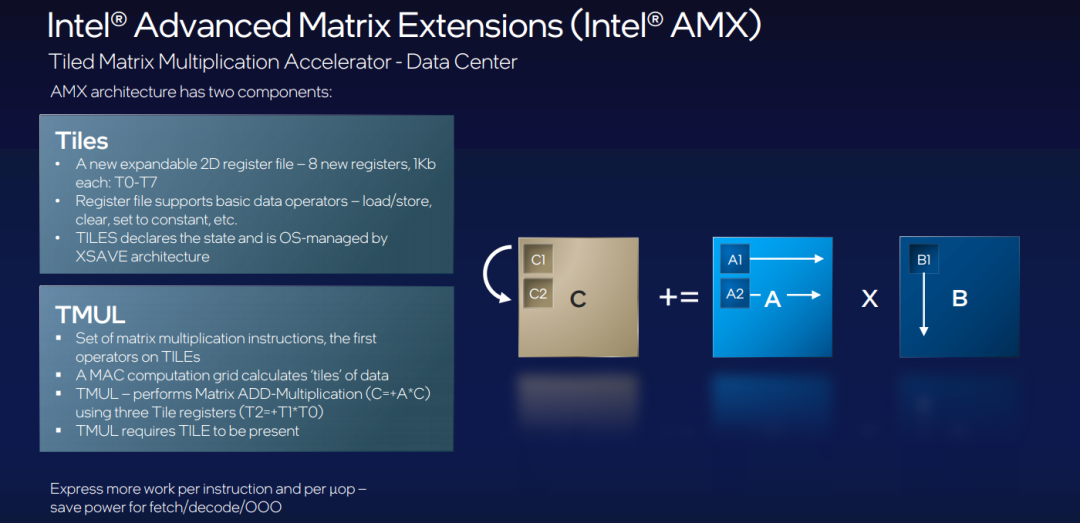
Intel AMX功能实现矩阵计算的原理
AVX-512更多的是进行向量算术运算,而AMX则是针对矩阵的计算指令集。数据会通过外部接口从CPU内部的一致性内存里依次存入到tiles的TMM寄存器里。一旦数据准备好,TMUL引擎就会进行两个TMM寄存器里数据的乘法运算,再将结果与TMM0寄存器里的数据进行累加运算。与此同时,CPU Core会给出命令进行调度,使得外部数据能够源源不断地存放到已经空了的TMM寄存器里,保证矩阵的乘加运算能够不间断地执行下去。可以看到,这一计算过程类似于NVIDIA GPU里Tensor Core对数据的处理方式。由于Tiles和TMUL引擎都是独立于CPU Core的部件,因此矩阵计算过程将不需要CPU的过多参与,也就不会占用CPU过多的时钟周期。
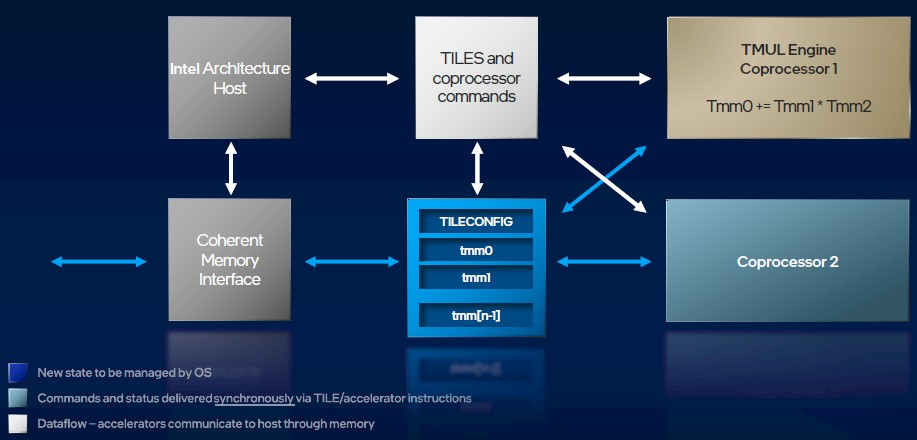
CPU和AMX计算单元同步运行的流程
由于一个CPU里的Tiles和TMUL引擎可以有很多个,因此AMX功能将会对CPU的矩阵计算产生可观的加速效果。
在CPU架构体系上,AMX扩展指令的实现方式与添加AVX2/AVX512指令集的方式类似,无需对整个体系结构进行任何特殊更改。由于Tiles与主机的内存访问机制保持一致,因此AMX指令在指令流中可以与内存加载/存储操作同步。和其它扩展一样,AMX中的各种扩展指令完全可以与其它x86代码扩展指令(如AVX512等)交互使用。
虽然Intel没有做过多的应用方面的说明,但AMX这一加速计算的扩展功能显然可以应用到推荐、自然语言处理、图像处理和其它常见的AI负载训练上。
总 结
Intel下一代的Sapphire Rapids CPU在外部硬件接口特性上有了大幅度的更新,这往往会使得人们忽略芯片内部针对具体应用所做的优化功能。在AI时代,Xeon CPU在推理计算领域站住脚跟后,下一个目标必然就是训练计算领域。这不仅是Intel自身为了拓展CPU应用空间必然会做的事情,也是广大用户基于低成本AI训练提出的实际需求。更不要说,AI训练领域的硬件利润是如此的丰厚呢!当然,CPU在AI训练方面主要还是针对中小型模型。对于大规模的AI模型,Intel将用其Xe HPC GPU去挑战NVIDIA GPU目前在AI训练领域的统治地位。



